
Hello developers and programmers! We are announcing the very first version of Beatoven.ai Software Development Kit (SDK). This open source software development kit is a Python-based software package that enables technical users and developers to integrate Beatoven.ai’s music composition abilities into their apps and workflows.
This brand new SDK is built on top of the Beatoven.ai’s public API to provide a simple yet powerful interface to Beatoven.ai’s music composition capabilities to abstract features like composing new tracks and listing created tracks. See the installation and usage example at our GitHub documentation.
Software Development Kits have been hugely successful in lowering the barrier for developers to adopt complex software product workflows into their applications. In recent years, Google Cloud SDK, OpenAI API library, etc are good examples of similar projects that have been widely adopted by the developer community. We truly believe that there are many creative applications and ideas that can benefit from the royalty-free music Beatoven offers and hence we wish to build along with our community.
Alright! Now we also look at a sample project that showcases the utilisation of the public Beatoven.ai SDK.
Sample Project – Story Score
Story-Score is a sample project that aims at automatically creating background scores for textual stories using Beatoven.ai.
Given an input text sentence, the story-score project creates a speech audio with an appropriate background score. This project utilizes deep learning models hosted at Huggingface Hub and Beatoven.ai SDK to create the appropriate background score based on the speech mood. Let’s have a look at the following input text and the corresponding generated audio output.
Input Text 1 (Example)
“Oh my God, that was so scary. The ghost of Colonel Sanders was eating at my local KFC.”
Generated Audio Output 1
Input Text 2 (Example)
“As Rachel was looking around, everyone was in happy spirits as they were dancing!”
Generated Audio Output 2
How does this work?
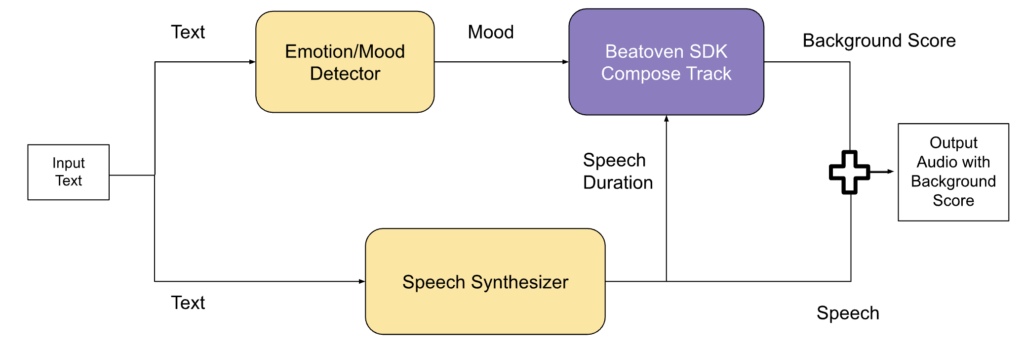
Story-score takes text input and utilises a custom voice embedding to create speech audio. You can select your own embedding as needed. Also, the emotion or mood associated with the text is detected using another emotion classification model. Both these models are publicly available on the Huggingface Hub for non-commercial usage. Further, the synthesized speech duration and mood parameter is passed to the Beatoven.ai SDK to create a track that can be utilised as a background score. Finally, the speech is combined with the composed track to create the audio with a background score. See notebook for source code.
The example audio created above is for a cinematic genre. There are other customisation options for music composition like genre, tempo, mood, choice of instruments and more. Explore Beatoven.ai for a full range of music composition capabilities.
Note: Story-score is only a sample project to showcase usage of Beatoven.ai SDK, we do not recommend it for any commercial production use cases.
Similar to most prominent SDK tools, Beatoven.ai authentication mechanism is based on API keys. If you are interested in using the SDK, please get in touch at hello@beatoven.ai. We would be glad to support your use-case(s) and issue an API key for your application.